The Spaghetti code challenge. Source: Wikimedia Commons, Plamen petkov 92, CC-BY-SA 4.0
As big software packages become a commonplace in geodynamics, which skills should a geodynamicist aim at having in software development? Which techniques should be considered a minimum standard for our software? This week Rene Gassmöller, project scientist at UC Davis, Computational Infrastructure for Geodynamics, shares his insights on the best practices to make scientific software better, and how we can work to translate these into our field. Enjoy the read!

Rene Gassmöller
Nowadays we often equate geodynamics with computational geodynamics. While there are still interesting analytical studies to be made, and important data to be gathered, it is increasingly common that PhD students in geodynamics are expected to work exclusively on data interpretation, computational models, and in particular the accompanying development of geodynamic software packages. But as it turns out, letting an unprepared PhD student (or unprepared postdoc or faculty member for that matter) work on a big software package is a near guarantee for the project to develop into a sizeable bowl of spaghetti code (see figure above for a representative illustration).
Note, that I intentionally write about ‘software packages’ instead of ‘code’, as many of these packages — think of Gplates (Müller et al, 2018), ObsPy (Krischer et al, 2015), FeniCS (Alneas et al, 2015) , or the project I am working on, ASPECT (Heister et al, 2017) — have necessarily left the stage of a quickly written ‘code’ for a single purpose, and developed into multi-purpose tools with a complex internal structure. With this growing complexity, the activity of scientific ‘coding’ evolved into ‘developing software’. However, when students enter the field of geophysics, they are rarely prepared for this challenge. Hannay et al. (2009) report that while researchers typically spend 30% or more of their time developing software, 90% of them are primarily self-taught, and only few of them received formal training for writing software, including tests and documentation. Nobody told them: Programming and engineering software are two very different things. Many undergraduate and graduate geoscience curricula today include classes about the basics of programming (e.g. in Python, R, or Matlab), and also discuss numerical and computational methods. While these concepts are crucial for solving scientific problems, they are not sufficient for managing the complexity of growing scientific software. Writing a 50-line script is a very different task from contributing to an inherited and poorly documented PhD project of 1,000 lines, which again is very different from managing a multi-developer project of 100,000 lines of source code. A recurring theme is that these differences are only discovered when damage has already been done. Hannay et al. (2009) note:
Codes often start out small and only grow large with time as the software proves its usefulness in scientific investigations. The demand for proper software engineering is therefore seldom visible until it is “too late”.
But what are these ‘proper software engineering techniques’?
Best practices vs. Best techniques in practice
In a previous blog post, Krister Karlsen already discussed the value of version control systems for reproducibility of computational research. It is needless to say that these systems (originally also termed source code control systems, e.g. Rochkind, 1975) are just as valuable for scientific software development as they are for reproducibility of results. However, they are not sufficient for developing reliable scientific software. Wilson et al. (2014) summarize a list of 8 best practices that make scientific software better:
- Write programs for people, not computers.
- A program should not require its readers to hold more than a handful of facts in memory at once.
- Make names consistent, distinctive, and meaningful.
- Make code style and formatting consistent.
- Let the computer do the work.
- Make the computer repeat tasks.
- Save recent commands in a file for re-use.
- Use a build tool to automate workflows.
- Make incremental changes.
- Work in small steps with frequent feedback and course correction.
- Use a version control system.
- Put everything that has been created manually in version control.
- Don’t repeat yourself (or others).
- Every piece of data must have a single authoritative representation in the system.
- Modularize code rather than copying and pasting.
- Re-use code instead of rewriting it.
- Plan for mistakes.
- Add assertions to programs to check their operation.
- Use an off-the-shelf unit testing library.
- Turn bugs into test cases.
- Use a symbolic debugger.
- Optimize software only after it works correctly.
- Use a profiler to identify bottlenecks.
- Write code in the highest-level language possible.
- Document design and purpose, not mechanics.
- Document interfaces and reasons, not implementations.
- Refactor code in preference to explaining how it works.
- Embed the documentation for a piece of software in that software.
- Collaborate.
- Use pre-merge code reviews.
- Use pair programming when bringing someone new up to speed and when tackling particularly tricky problems.
- Use an issue tracking tool.
There is a lot to be said about each of these techniques, but that would be beyond the scope of this blog post (please see Wilson et al.’s excellent and concise paper if you are interested). What I would like to emphasize here is that these techniques are often requested, but rarely taught. What are peer code reviews? How do I gradually introduce tests and refactor a legacy code? Who knows if it is better to use unit testing, integration testing, regression testing, or benchmarking for a given change of the code? And do I really need to know the difference? After all, a common argument against using software development techniques in applied computational science disciplines boils down to:
- We can not expect these software development techniques from geodynamicists.
- We should not employ the same best practices as Google, Amazon, Apple, because they do not apply to us.
- There is no time to learn/apply these techniques, because we have to conduct our research, write our publications, secure our funding.
While from a philosophical standpoint it is easy to dismiss these statements as not adhering to best practices, and possibly impacting the reliability of the created software, it is harder to tackle them from a practical perspective. Of course it is true that implementing a sophisticated testing infrastructure for a one-line shell command is neither useful nor necessary. Maybe the same is true for a 20 line script that is written to specifically convert one dataset into another, but in this case putting it under version control would already be useful in order to record your process and apply it to other datasets. And from my own experience it is extraordinarily easy to miss the threshold at 40-100 lines at which writing documentation and implementing first testing procedures become crucial to avoid cursing yourself in the future for not explaining what you did and why you did it. So why are there detailed instructions for lab notes and experimental procedures, but not for geodynamic software design and reliability of scientific software? Geoscience, chemistry, and physics have established multi-semester lab and field exercises, to drill students towards careful scientific analysis. Should we develop comparable exercises for scientific software development (beyond numerical methods and basic programming)? How would an equivalent of these classes look like for computational methods? And is there a point where the skills of software development and geodynamics research grow so far apart we have to consider them separately and establish a unique career track, such as the Research Software Engineer that is becoming more popular in the UK?
In my personal opinion we have made great progress over the last years in defining best practices for scientific software (see e.g. https://software.ac.uk/resources/online-sustainability-evaluation, or https://geodynamics.org/cig/dev/best-practices/). However, it is still considered a personal task to acquire the necessary skills and to find the correct balance between careful engineering and overdesigning software. Establishing courses and resources that discuss these questions could greatly benefit our community, and allow for a more reliable scientific progress in geodynamics.
Collaborative software development – The overlooked social challenge
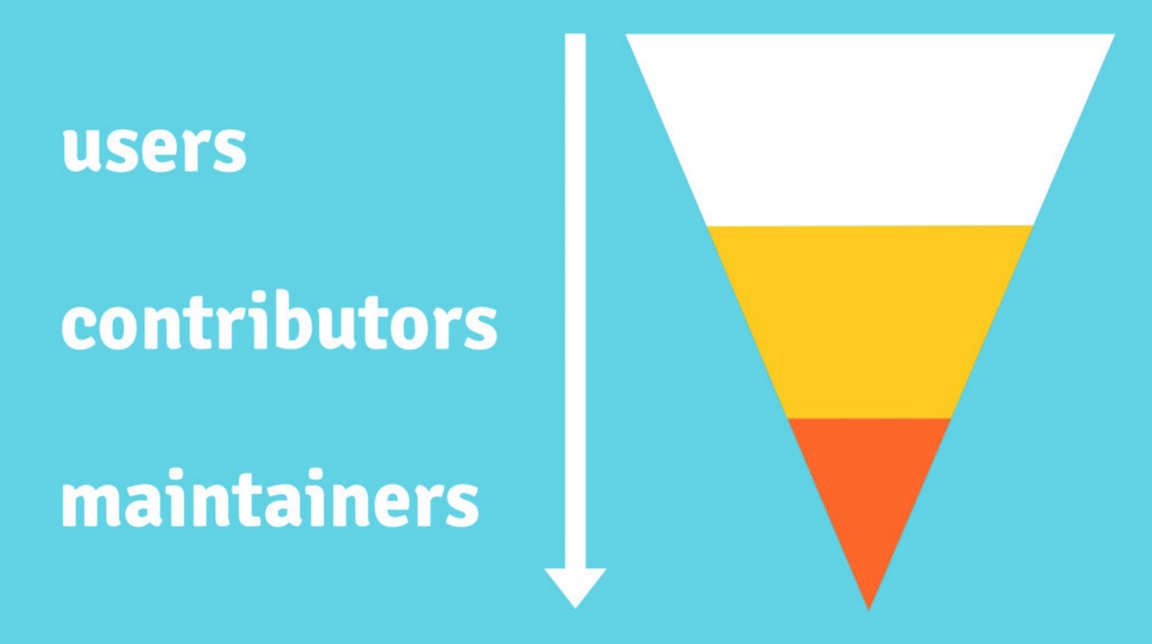
The contributor funnel. The atmosphere and usability of a project influence how many users will join a project, how long they stick around, and if they will take responsibility for the project by contributing to it or eventually become maintainers. Credit: https://opensource.guide/
Now that we covered every topic a scientist can learn about scientific software development in a single blog post, what can go wrong when you put several of them together to work on a software package? Needless to say, a lot. No matter if your software project is a closed-source, intra-workgroup project, or an open-source project with users and developers spread over different continents, things are going to get exponentially more complicated the more people work on your software. Not only does discussion and interaction take more time, there will also be conflicting ideas about computational methods, software design, or implementation. Using state-of-the-art tools like collaborative development platforms (Github, Gitlab, Bitbucket, pick your favourite) and modern discussion channels like chats (Slack, Gitter), forums (Discourse), or video conferences (Skype, Hangouts, Zoom) can alleviate a part of the communication barriers. But ultimately, the social challenges remain. How does a project decide between competing goals of flexibility and performance? Who is going to enforce a code of conduct in a project to keep the development environment open and friendly? Does a project create a welcoming atmosphere that invites new contributions, or does it repel newcomers by unrealistic standards and inappropriate behavior? How should maintainers of scientific software deal with unrealistic feature requests by users? How to encourage new users to become contributors and take responsibility for the software they benefit from? How to compromise or combine providing improvements to the upstream project versus publishing them as scientific papers? How to provide credit to contributors?
In my opinion it is unfortunate that these questions about scientific software projects are even less discussed than the (now increasing) awareness of reproducibility. On the bright side, there is already a trove of experiences in the open-source community. The same questions about attribution and credit, collaboration and community-management, and correctness and security have been discussed over the past decades in open-source projects all over the world, and nowadays a good number of resources provide guidance, such as https://opensource.guide/, or the excellent book ‘How to Run a Successful Free Software Project’ (Fogel, 2017). Not all of it can be transferred to science, but we would waste time and energy to dismiss these experiences and instead repeat their mistakes.
Let us talk about engineering scientific software
I realize that in this blog post I opened more questions than I answered. Maybe that is because I am not aware of the answers that are already out there. But maybe it is also caused by a lack of attention that these questions receive. I feel that there are no established guidelines for which software development skills a geodynamicist should have, and what techniques should be considered a minimum standard for our software. If that is the case, I would invite you to have a discussion about it. Maybe we can agree on a set of guidelines and improve the state of software in geodynamics. But at the very least I hope I inspired some thought about the topic, and provided some resources to learn more about a discussion that will likely grow more important over the coming years.
References: M. S. Alnaes, J. Blechta, J. Hake, A. Johansson, B. Kehlet, A. Logg, C. Richardson, J. Ring, M. E. Rognes and G. N. Wells. The FEniCS Project Version 1.5. Archive of Numerical Software, vol. 3, 2015, http://dx.doi.org/10.11588/ans.2015.100.20553. Fogel, K. (2017). Producing Open Source Software: How to Run a Successful Free Software Project. O'Reilly Media, 2nd edition. Hannay, J. E., MacLeod, C., Singer, J., Langtangen, H. P., Pfahl, D., & Wilson, G. (2009). How do scientists develop and use scientific software?. In Proceedings of the 2009 ICSE workshop on Software Engineering for Computational Science and Engineering (pp. 1-8). IEEE Computer Society. Heister, T., Dannberg, J., Gassmöller, R., & Bangerth, W. (2017). High accuracy mantle convection simulation through modern numerical methods–II: realistic models and problems. Geophysical Journal International, 210(2), 833-851. Krischer, L., Megies, T., Barsch, R., Beyreuther, M., Lecocq, T., Caudron, C., & Wassermann, J. (2015). ObsPy: A bridge for seismology into the scientific Python ecosystem. Computational Science & Discovery, 8(1), 014003. Müller, R.D., Cannon, J., Qin, X., Watson, R.J., Gurnis, M., Williams, S., Pfaffelmoser, T., Seton, M., Russell, S.H. & Zahirovic, S. (2018). GPlates–Building a Virtual Earth Through Deep Time. Geochemistry, Geophysics, Geosystems. Open Source Guides. https://opensource.guide/. Oct, 2018. Rochkind, M. J. (1975). The source code control system. IEEE transactions on Software Engineering, (4), 364-370. Wilson, G., Aruliah, D.A., Brown, C.T., Hong, N.P.C., Davis, M., Guy, R.T., Haddock, S.H., Huff, K.D., Mitchell, I.M., Plumbley, M.D. and Waugh, B. (2014). Best practices for scientific computing. PLoS biology, 12(1), e1001745.



{kind=link}