

Krister with his bat-signal shirt for reproducibility.
We’ve all been there – you’re reading through a great new paper, keen to get to the Data Availability only to find nothing listed, or the uninspiring “data provided on request”. This week Krister Karlsen, PhD student from the Centre for Earth Evolution and Dynamics (CEED), University of Oslo shares some context and tips for increasing the reproducibility of your research from a computational science perspective. Spread the good word and reach for the “Gold Standard”!
Historically, computational methods and modelling have been considered the third avenue of the sciences, but they are now some of the most important, paralleling experimental and theoretical approaches. Thanks to the rapid development of electronics and theoretical advances in numerical methods, mathematical models combined with strong computing power provide an excellent tool to study what is not available for us to observe or sample (Fig. 1). In addition to being able to simulate complex physical phenomena on computer clusters, these advances have drastically improved our ability to gather and examine high-dimensional data. For these reasons, computational science is in fact the leading tool in many branches of physics, chemistry, biology, and geodynamics.

Figure 1: Time–depth diagram presenting availability of geodynamic data. Modified from (Gerya, 2014).
A side effect of the improvement of methods for simulation and data gathering is the availability of a vast variety of different software packages and huge data sets. This poses a challenge in terms of sufficient documentation that will allow the study to be reproduced. With great computing power, comes great responsibility.
“Non-reproducible single occurrences are of no significance to science.” – Popper (1959)
Reproducibility is the cornerstone of cumulative science; the ultimate standard by which scientific claims are judged. With replication, independent researchers address a scientific hypothesis and build up evidence for, or against, it. This methodology represents the self-correcting path that science should take to ensure robust discoveries; separating science from pseudoscience. Reports indicate increasing pressure to publish manuscripts whilst applying for competitive grants and positions (Baker, 2016). Furthermore, a growing burden of bureaucracy takes away precious time designing experiments and doing research. As the time available for actual research is decreasing, the number of articles that mention a “reproducibility crisis?” are rising towards the present day peak (Fig. 2). Does this mean we have become sloppy in terms of proper documentation?
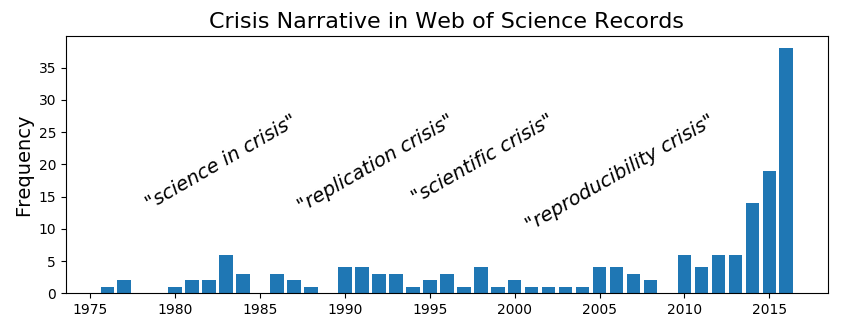
Figure 2: Number of titles, abstracts, or keywords that contain one of the following phrases: “reproducibility crisis,” “scientific crisis,” “science in crisis,” “crisis in science,” “replication crisis,” “replicability crisis”, found in the Web of Science records. Modified from (Fanelli, 2018).
Are we facing a reproducibility crisis?
A survey conducted by Nature asked 1,576 researchers this exact question, and reported 52% responded with “Yes, a significant crisis,” and 38% with “Yes, a slight crisis” (Baker, 2016). Perhaps more alarming is that 70% report they have unsuccessfully tried to reproduce another scientist’s findings, and more than half have failed to reproduce their own results. To what degree these statistics apply to our own field of geodynamics is not clear, but it is nonetheless a timely remainder that reproducibility must remain at the forefront of our dissemination. Multiple journals have implemented policies on data and software sharing upon publication to ensure the replication and reproduction of computational science is maintained. But how well are they working? A recent empirical analysis of journal policy effectiveness for computational reproducibility sheds light on this issue (Stodden et al., 2018). The study randomly selected 204 papers published in Science after the implementation of their code and data sharing policy. Of these articles, 24 contained sufficient information, whereas for the remaining 180 publications the authors had to be contacted directly. Only 131 authors replied to the request, of these 36% provided some of the requested material and 7% simply refused to share code and data. Apparently the implementation of policies was not enough, and there is still a lot of confusion among researchers when it comes to obligations related to data and code sharing. Some of the anonymized responses highlighted by Stodden et al. (2018) underline the confusion regarding the data and code sharing policy:

Putting aside for the moment that you are, in many cases, obliged to share your code and data to enhance reproducibility; are there any additional motivating factors in making your computational research reproducible? Freire et al. (2012) lists a few simple benefits of reproducible research:
1. Reproducible research is well cited. A study (Vandewalle et al., 2009) found that published articles that reported reproducible results have higher impact and visibility.
2. Code and software comparisons. Well documented computational research allows software developed for similar purposes to be compared in terms of performance (e.g. efficiency and accuracy). This can potentially reveal interesting and publishable differences between seemingly identical programs.
3. Efficient communication of science between researchers. New-comers to a field of research can more efficiently understand how to modify and extend an existing program, allowing them to more easily build upon recently published discoveries (this is simply the positive counterpart to the argument made against software sharing earlier).
“Replicability is not reproducibility: nor is it good science.” – Drummond (2009)
I have discussed reproducibility over quite a few paragraphs already, without yet giving it a proper definition. What precisely is reproducibility? Drummond (2009) proposes a distinction between reproducibility and replicability. He argues that reproducibility requires, at the minimum, minor changes in experiment or model setup, while replication is an identical setup. In other words, reproducibility refers to a phenomenon that can be predicted to recur with slightly different experimental conditions, while replicability describes the ability to obtain an identical result when an experiment is performed under precisely the same conditions. I think this distinction makes the utmost sense in computational science, because if all software, data, post-processing scripts, random number seeds and so on, are shared and reported properly, the results should indeed be identical. However, replicability does not ensure the validity of the scientific discovery. A robust discovery made using computational methods should be reproducible with a different software (made for similar purposes, of course) and small perturbations to the input data such as initial conditions, physical parameters, etc. This is critical because we rarely, if ever, know the model inputs with zero error bars. A way for authors to address such issues is to include a sensitivity analysis of different parameters, initial conditions and boundary conditions in the publication or the supplementary material section.

Figure 3: Illustration of the “spectrum of reproducibility”, ranging from not reproducible to the gold standard that includes code, data and executable files that can directly replicate the reported results. Modified from (Peng, 2011).
However, the gold standard of reproducibility in computation-involved science, like geodynamics, is often described as what Drummond would classify as replication (Fig. 3). That is, making all data and code available to others to easily execute. Even though this does not ensure reproducibility (only replicability), it provides other researchers a level of detail regarding the work-flow and analysis that is beyond what can usually be achieved by using common language. And this deeper understanding can be crucial when trying to reproduce (and not replicate) the original results. Thus replication is a natural step towards reproduction. Open-source community codes for geodynamics, like eg. ASPECT (Heister et al., 2017), and more general FEM libraries like FEniCS (Logg et al., 2012), allows for friction-free replication of results. An input-file describing the model setup provides a 1-to-1 relation to the actual results1 (which in many cases is reasonable because the data are too large to be easily shared). Thus, sharing the post-processing scripts accompanied by the input file on eg. GitHub, will allow for complete replication of the results, at low cost in terms of data storage.
Light at the end of the tunnel?
In order to improve practices for reproducibility, contributions will need to come from multiple directions. The community needs to develop, encourage and maintain a culture of reproducibility. Journals and funding agencies can play an important role here. The American Geosciences Union (AGU) has shared a list of best practices regarding research data2 associated with a publication:
• Deposit the data in support of your publication in a leading domain repository that handles such data.
• If a domain repository is not available for some of all of your data, deposit your data in a general repository such as Zenodo, Dryad, or Figshare. All of these repositories can assign a DOI to deposited data, or use your institution’s archive.
• Data should not be listed as “available from authors.”
• Make sure that the data are available publicly at the time of publication and available to reviewers at submission—if you are unable to upload to a public repository before submission, you may provide access through an embargoed version in a repository or in datasets or tables uploaded with your submission (Zenodo, Dryad, Figshare, and some domain repositories provide embargoed access.) Questions about this should be sent to journal staff.
• Cite data or code sets used in your study as part of the reference list. Citations should follow the Joint Declaration of Data Citation Principles.
• Develop and deposit software in GitHub which can be cited, or include simple scripts in a supplement. Code in Github can be archived separately and assigned a DOI through Zenodo for submission.
In addition to best practice guidelines, wonderful initiatives from other communities include a research prize. The European College of Neuropsychopharmacology offers a (11,800 USD) award for negative results, more specifically for careful experiments that do not confirm an accepted hypothesis or previous result. Another example is the International Organization for Human Brain Mapping who awards 2,000 USD for the best replication study − successful or not. Whilst not a prize per se, at recent EGU General Assemblies in Vienna the GD community have held sessions around the theme of failed models. Hopefully, similar initiatives will lead by example so that others in the community will follow.
1To the exact same results, information about the software version, compilers, operating system etc. would also typically be needed.
2 AGU’s definition of data includes all code, software, data, methods and protocols used to produce the results here.
References AGU, Best Practices. https://publications.agu.org/author-resource-center/publication-policies/datapolicy/data-policy-faq/ Accessed: 2018-08-31. Baker, Monya. Reproducibility crisis? Nature, 533:26, 2016. Drummond, Chris. Replicability is not reproducibility: nor is it good science. 2009. Fanelli, Daniele. Opinion: Is science really facing a reproducibility crisis, and do we need it to?Proceedings of the National Academy of Sciences, 115(11):2628–2631, 2018. Freire, Juliana; Bonnet, Philippe, and Shasha, Dennis. Computational reproducibility: state-of-theart, challenges, and database research opportunities. In Proceedings of the 2012 ACM SIGMOD international conference on management of data, pages 593–596. ACM, 2012. Gerya, Taras. Precambrian geodynamics: concepts and models. Gondwana Research, 25(2):442–463, 2014. Heister, Timo; Dannberg, Juliane; Gassm"oller, Rene, and Bangerth, Wolfgang. High accuracy mantle convection simulation through modern numerical methods. II: Realistic models and problems. Geophysical Journal International, 210(2):833–851, 2017. doi: 10.1093/gji/ggx195. URL https://doi.org/10.1093/gji/ggx195. Logg, Anders; Mardal, Kent-Andre; Wells, Garth N., and others, . Automated Solution of Differential Equations by the Finite Element Method. Springer, 2012. ISBN 978-3-642-23098-1. doi: 10.1007/978-3-642-23099-8. Peng, Roger D. Reproducible research in computational science. Science, 334(6060):1226–1227, 2011. Popper, Karl Raimund. The Logic of Scientific Discovery . University Press, 1959. Stodden, Victoria; Seiler, Jennifer, and Ma, Zhaokun. An empirical analysis of journal policy effectiveness for computational reproducibility. Proceedings of the National Academy of Sciences , 115(11):2584–2589, 2018. Vandewalle, Patrick; Kovacevic, Jelena, and Vetterli, Martin. Reproducible research in signal processing. IEEE Signal Processing Magazine , 26(3), 2009


