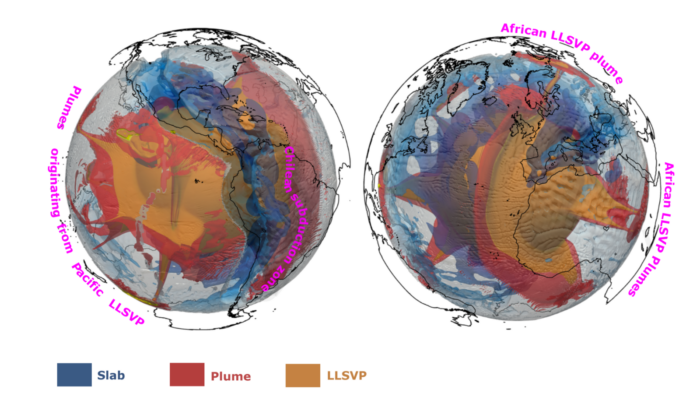
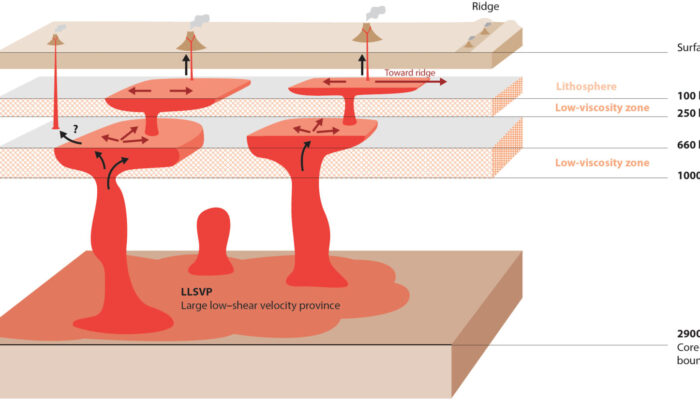
The EGU General Assembly is only a few weeks away, and attendees are starting to plan their schedules into what promises to be a week full of exiciting presentations and events. Don’t know where to start planning your week? We got you covered! In today’s blog, we highlight the key events of Geodynamics Division and give you some key tips to get the most out of the week. To access the e ...[Read More]
The Geodynamics Division @ EGU26