
On February 23 and 25, 2021, the Computational Infrastructure for Geodynamics (CIG) organized its first Developer Workshop. CIG is a community organization that advances Earth science by developing and disseminating software for geophysics and related fields. The goal of the meeting was to bring the CIG developer community together to discuss current issues and opportunities. Brad Aagaard (U.S. Geological Survey), on behalf of the organizers, shares with us what was discussed and the new initiatives that are being organized as a result of this meeting.

Brad Aagaard, U.S. Geological Survey
I first had the idea for a CIG developers workshop 5 years ago. I was confident developer teams would benefit from exchanging ideas to improve their software development process, but I did not have a particular set of topics in mind. A CIG community workshop in October 2020 raised some concrete issues for developers to discuss and the timing seemed right to hold a developers workshop in early 2021 since CIG would be writing a proposal to the National Science Foundation in the spring of 2021 seeking continued funding. Thanks to the rest of the organizing committee including Jed Brown (University of Colorado, Boulder), Catherine M. Cooper (Washington State University), Rene Gassmoeller (University of Florida), Lorraine Hwang (University of California, Davis), and Marc Spiegelman (Lamont-Doherty Earth Observatory, Columbia University); we developed a strong workshop agenda and focused on four themes
-
Expanding the CIG software developer community;
-
Making CIG software more accessible to new users;
-
Identifying and leveraging common infrastructure; and
-
Leveraging collective wisdom to make CIG software better and easier to develop and maintain.
The 43 workshop participants represented developers of CIG community codes, those interested in contributing to the community codes, and researchers interested in improving their own codes. We held the workshop entirely online and devoted most of the time to group discussion, which was broken into six sessions. The discussions were driven by responses from a detailed developer survey and a shorter user survey. Thirteen developer teams associated with 15 different computer modeling codes submitted responses; this provided information from the developers of all of the major CIG-related modeling codes as well as a few other codes. Thirty-one users submitted responses; this represents a small fraction of the total users of the codes (we obtain a much better response rate when surveys are associated with user-related workshops). I introduced each session by summarizing relevant results from the developer and user surveys.
Most of the developer teams indicated that there is a much greater demand for developers to implement and test new features and update documentation than they have time for. Users indicated that troubleshooting simulation setup was the most time-consuming step and the most challenging step in their modeling workflow; this demonstrates the need for developers to produce both good documentation and good error messages that help users resolve problems. We designed the workshop discussions to address these challenges. In the following sections I highlight important points from the sessions for each of the workshop themes.
Expanding the CIG software developer community
The discussion centered on how to increase the number of developers to meet the demand for new features and documentation and how to properly acknowledge contributions from the community. A developer triangle (or developer pyramid) is often used to describe distribution of users and developers and the progression along the way. New users (usually the largest group) form the base of the triangle, with experienced users above them, followed by contributors, developers, and maintainers, the smallest group, at the top (Figure 1). Good support through documentation, cookbook examples, tutorials, and responding to questions is critical for maintaining a strong base of new users, with many climbing the ladder to become experienced users. Hackathons provide experienced users exposure to making small contributions and becoming familiar with the source code and software development workflow. Developer documentation, clean plug-and-play interfaces, encouragement, and mentoring are all important for obtaining useful contributions. Progressing from contributor to developer or from developer to maintainer usually involves extended duration and close collaboration with other developers and maintainers. Support for all levels of users is critical for developing a pipeline that generates a sufficient number of developers and maintainers to sustain a community code. Postdoctoral programs have a particularly important role in this process, because postdocs engage in close collaboration over 1-2 years at the stage when they have often developed sufficient expertise as graduate students to transition from contributors to developers.
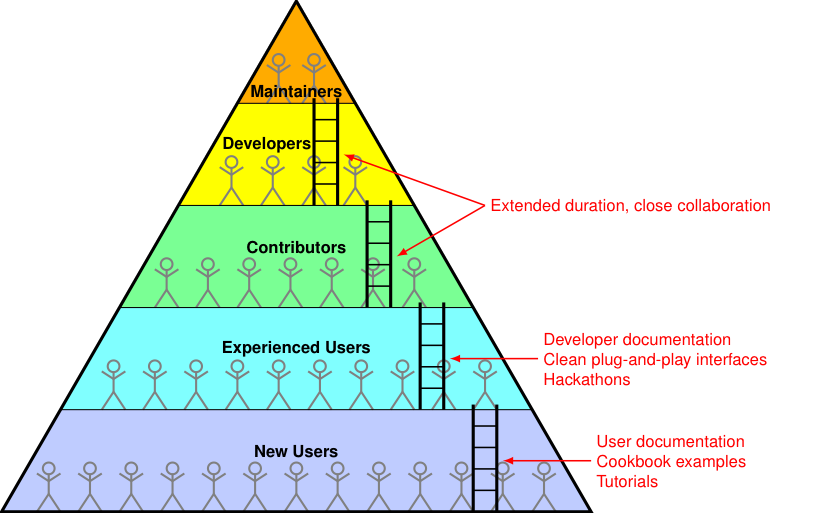
Figure 1: Developer triangle (sometimes called a developer pyramid) showing the progression from new users to maintainers along with key conditions for people to climb the ladder to the next level.
Our discussion of recognizing contributions to community codes concluded that developer teams need to recognize contributions in multiple ways, especially in ways that document the impact of contributions. For example, students and postdocs gain exposure when they are listed as contributors in release notes, software manuals, and community forums or mailing lists; this helps them obtain faculty and research positions. Demonstrating the impact of contributions becomes more important in faculty and research scientist advancement. Coauthorship on journal articles is the most direct way to demonstrate impact, but in many cases, collaboration may be insufficient to warrant coauthorship. To better address these cases, developer teams need to make it easy for users to cite contributions associated with features they use. Likewise, promotion committees in academia, research organizations, and industry need to reward significant contributions to community codes.
Some additional actions that CIG and related modeling communities can take to facilitate a strong suite of users include
-
Maintain a catalog of recommended building blocks, e.g., libraries and packages, for potential use in developing new codes;
-
Maintain a list of teaching, coding, and numerical modeling resources;
-
Forge partnerships with organizations running software carpentry workshops and helping develop ones with a focus on geodynamics; and
-
Provide Research Experiences to Undergraduates (REUs) in geodynamics modeling with an emphasis on increasing participation from underrepresented minority groups.
Identifying and leveraging common software infrastructure
One of the workshop objectives was to identify the potential for developing common infrastructure to reduce duplicative development efforts. We focused on the potential for standardizing output and developing a common application programming interface (API) for specifying values for material properties, initial conditions, or boundary conditions. Adopting standards for these two areas would greatly facilitate connecting processes at different scales modeled by different codes.
The responses to the developers survey indicated that most of the modeling codes output similar information using similar standard formats. From the discussion we recommend that CIG
-
Form a working group to develop standard layouts for VTK, HDF5+Xdmf, and netCDF files;
-
Leverage standards that have already been developed by other organizations where possible;
-
Consider providing web interfaces for inspection, simple processing, and simple visualization; and
-
Identify possible common post-processing algorithms and scripts.
The discussion also covered challenges associated with storing results from higher order discretizations, which are rarely supported in visualization tools, and reducing storage requirements of output from massively parallel simulations using compression, including lossy compression. The push towards exascale computing has generated several projects, such as Alpine/ZFP and Conduit, that address these issues and are worthy of investigation to assess their utility.
A second session focused on the feasibility of adopting a standard interface for specifying values for material properties, initial conditions, or boundary conditions. This session included presentations on three existing libraries within the CIG community. World Builder, used by ASPECT, targets specification of material properties by defining volumes within a domain using simple spatial features and assigning parameterizations and properties to the features. SpatialData, used by PyLith, provides an API for querying values in space along with several implementations; it supports georeferencing and unit conversion and is used for specifying values for material properties, initial conditions, and boundary conditions. The library easi, used by SeisSol, provides an API for mapping values from n-dimensional space to m-dimensional space; it supports several model types, which can be composed together to provide values for material properties and initial conditions. SpatialData and easi have similar APIs and functionality and would not be difficult to merge. Developing a standard API that could be used by most CIG modeling codes may be feasible, but it will be much more difficult than standardizing simulation output. For example, specifying values for material properties often requires knowing the composition and state variables in addition to the location. We recommend that CIG form a working group to assess use cases, scope, and outcomes of an API and a corresponding library.
Making CIG software more accessible to new users
The user survey showed that many CIG codes are used within a larger modeling workflow or are run many times for sensitivity analyses, uncertainty quantification, or inversions. Additionally, most users struggle with troubleshooting simulation setup, preparing simulation inputs, and post-processing results. Most of the discussion dovetailed from a presentation on the Pangeo project that illustrated the use of Jupyter notebooks and related software for integrating data, modeling, and visualization into computational narratives (interactive description of the modeling setup, simulation, and results). About one-third of the session participants indicated that they currently use Jupyter notebooks. There was broad interest in (you guessed it) forming a working group to assess how to best use Jupyter notebooks to improve modeling workflows across all levels of users within the CIG community.
Leveraging collective wisdom to make CIG software better and easier to develop and maintain
Domain scientists can learn a lot from computer scientists and computational scientists when it comes to software development. We devoted one session of the workshop to software development tools and another session to software development best practices. The principal conclusions from the discussion of developer tools include
-
CIG should encourage use of integrated development environments (IDEs) including providing resources showing how to set up an IDE and CIG should use IDEs in tutorials and hackathons;
-
CIG should provide test runners and consider using a repository-based continuous integration tool, such as GitHub Actions or GitLab Pipelines;
-
Singularity containers are likely the best path forward for helping people get CIG modeling codes installed on clusters, which requires parallel-processing libraries configured for the cluster hardware; and
-
CIG should encourage codes to provide online documentation, which has several advantages over PDF files, in addition to a PDF version.
The survey results showed that most of the developer teams follow many of the CIG Software Development Best Practices. As a result, the discussion focused largely on two areas where current practices could be improved. Most of the developer teams who responded to the survey do not provide the community with a regularly updated document that outlines priorities for software development with a rough timeline of when features might be implemented. However, several developer teams do use GitHub Issues to track feature requests. In fact, GitHub Issues tagged with milestones and GitHub Projects provide users with a more complete picture of the status of new features, because they often include a discussion of design decisions. The discussion identified the importance of developer teams engaging the community at least once a year to update development priorities. In an ideal world, following community engagement developer teams would provide both a developer plan document and track progress using tools, such as GitHub Issues and Projects.
Checkpointing was the second best practice that received considerable discussion. Although most codes implement checkpointing, they use their own implementations and they could be more efficient. The conclusion was that several general checkpointing tools are available that CIG should investigate to determine if they are useful for CIG modeling codes.
Summary
The CIG Developers Workshop resulted in a number of recommendations that we think will help expand the CIG developer community, make software more accessible to new users, and increase developer productivity through use of common infrastructure and best practices for software development. This includes building a broad user base with sufficient support through documentation, tutorials, user forums, hackathons, scientific workshops, and mentoring to maintain a healthy suite of software developers and maintainers. Communities also need to offer opportunities, like this workshop, for developer teams to interact with each other to exchange ideas, identify common infrastructure, and interact with users to discuss modeling workflows and development priorities. I am already looking forward to our next developers workshop.
Any use of trade, firm, or product names is for descriptive purposes only and does not imply endorsement by the U.S. Government.
Further reading
2021 CIG Developers Workshop webpage, highlights and links on the CIG Community Forum.