The 2025 Outstanding Early Career Scientist Award of the Geodynamics Division was awarded to Iris van Zelst in recognition of her outstanding ability to connect research fields including earthquake dynamics, planetary sciences and geodynamics, along with her profound engagement with science outreach and promotion of diverse and inclusive working enviroments. In this interview, Iris -also former EG ...[Read More]
Iris van Zelst – GD Outstanding ECS Award 2025
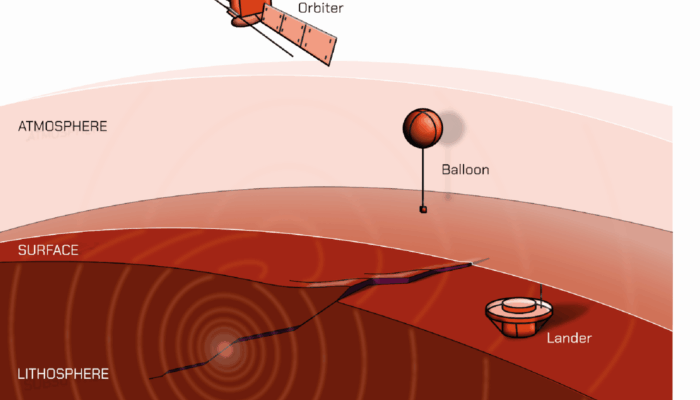
Different methods to potentially detect seismic waves on Venus: a broadband seismometer on the surface, a pressure sensor on a balloon in the atmosphere, and an airglow imager on an orbiter around Venus (credit: Iris van Zelst / Fabio Crameri; also see Garcia et al., 2024).

