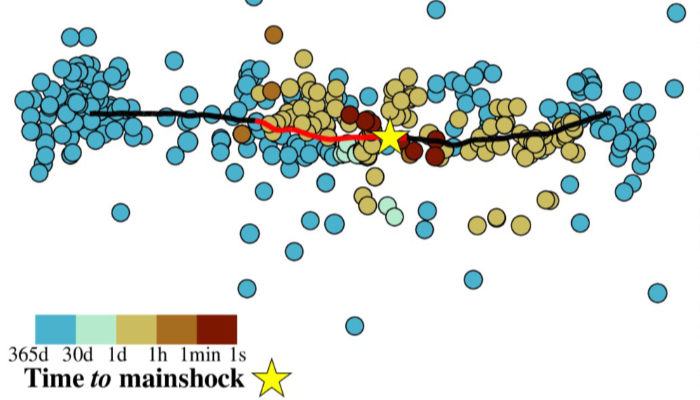
Introduction Despite advances in our understanding of rock mechanics, the frictional behavior of rocks, and the physics of instability in geological materials, the coexistence of slow and fast earthquakes, as well as various types of fault-zone seismic radiation such as tremor, remains enigmatic. Can fault mechanics and friction laws reproduce the full spectrum of observed seismicity? In this week ...[Read More]
Modeling the full spectrum of observed seismicity: Insights from friction laws, fault instability, and fault-zone mechanics