What is machine learning?
Artificial Intelligence, and its subfield of machine learning, is a very trending topic as it plays an increasing role in our daily life. Examples are: translation programs, speech recognition software in mobile phones and automatic completion of search queries. However, what value do these new techniques have for climate science? And how complicated is it to use them?
The idea behind machine learning is simple: a computer is not explicitly programmed to perform a particular task, but rather learns to perform a task based on some input data. There are various ways to do this, and machine learning is usually separated into three different domains: supervised learning, unsupervised learning and reinforcement learning. Reinforcement learning is of less interest to climate science, and will therefore not be touched upon here.
In supervised learning, the computer is provided both with the data and some information about the data: i.e. the data is labeled. This means that each chunk of data (usually called one sample) has a label. This label can be a string (e.g. a piece of text), a number or, in principle, any other kind of data. The data samples could be for example images of animals, and the labels the names of the species. The machine learning program then learns to connect images with labels and, when successfully trained, can correctly label new images of animals that it has not seen yet. This principle idea is sketched in Figure 1.
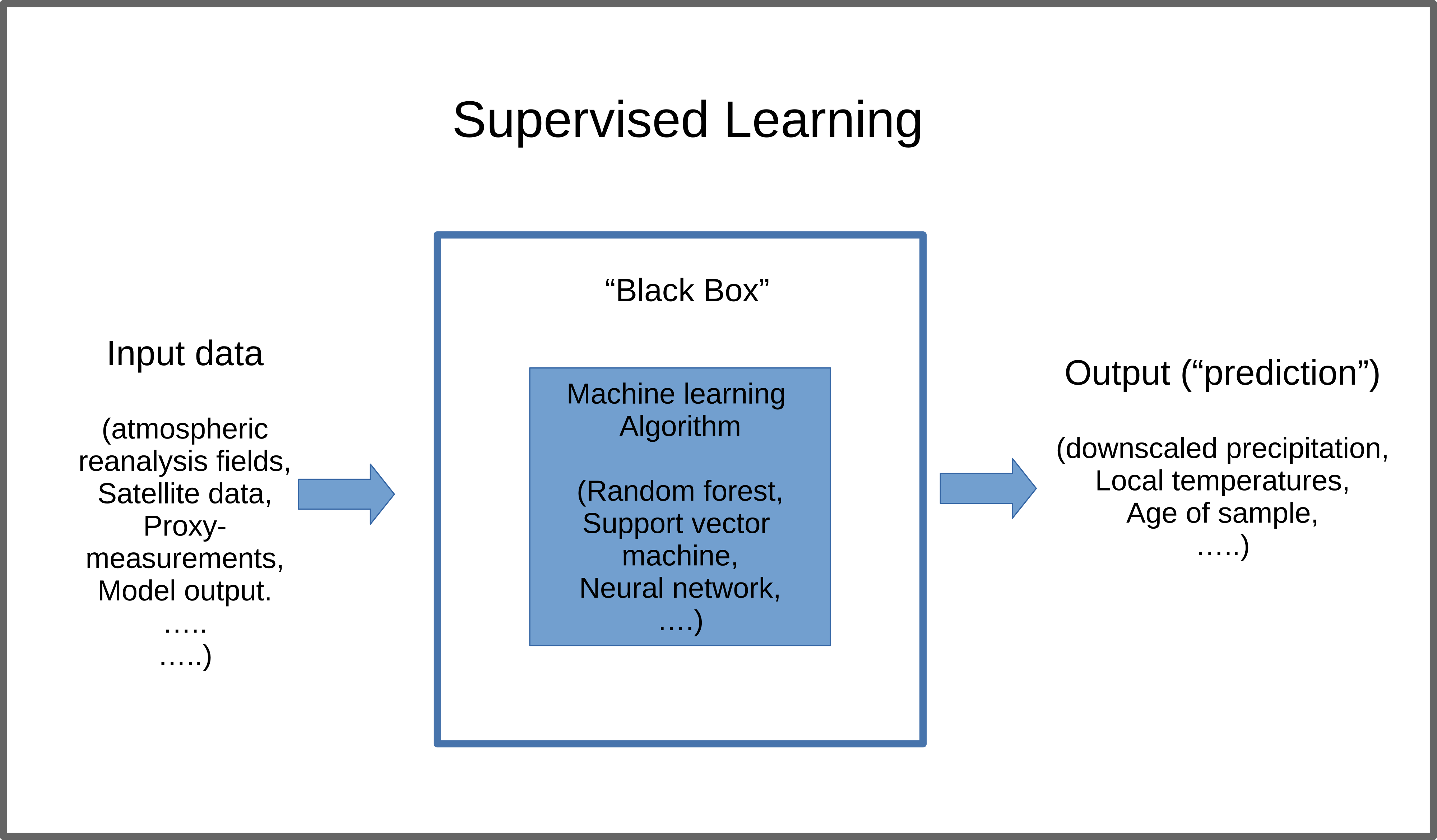
Figure 1: A schematic of supervised machine learning in climate science.
In a climate context, the “image” might be a rough global representation of for example surface pressure, and the label some local phenomenon like strong rainfall in a small region. This is sketched in Figure 2. Some contemporary machine learning methods can decide which features of a picture are related to its label with very little or no prior information. This is well comparable to certain types of human learning. Imagine being taught how to distinguish between different tree species by being shown several images of trees, each labeled with a tree name. After seeing enough pictures, you will be able to identify the tree species shown in images you had not seen before. How you managed to learn this may not be clear to you, but your brain manages to translate the visual input reaching your retina into information you can use to interpret and categorize successive visual inputs. This is exactly the idea of supervised machine learning: one presents the computer with some data and a description of the data, and then lets the computer figure out how to connect the two.

FIgure 2: example of using machine learning for predicting local rainfall.
In unsupervised learning, on the other hand, the machine learning program is presented with some data, without any additional information on the data itself (such as labels). The idea is that the program searches autonomously for structure or connections in the data This might be for example certain weather phenomena that usually occur together (e.g. very humid conditions in one place A, and strong rainfall in place B). Another example are “typical” patterns of the surface temperature of the ocean. These temperature patterns look slightly different every day, but with machine learning we can find a small number of “typical” configurations – which then can help in understanding the climate.
How difficult is it to implement machine learning techniques?
Machine learning techniques often sound complicated and forbidding. However, due to the widespread use of many machine learning techniques both in research and in commercial applications, there are many publicly available user-ready implementations. A good example is the popular python library scikit-learn1. With this library, classification or regression models based on a wide range of techniques can be constructed with a few lines of code. It is not necessary to know how the algorithm works exactly. If one has a basic understanding of how to apply and evaluate machine learning models, the methods themselves can to a large extent be treated as black-boxes. One simply uses them as tools to address a specific problem, and checks whether they work.
What can machine learning do for climate science?
By now you are hopefully convinced that machine learning methods are: 1) widely used and 2) quite easy to apply in practice. This however still leaves the most important question open: can we actually use them in climate science? And even more importantly: can they help us in actually understanding the climate system? In most climate science applications, machine learning tools can be seen as engineering tools. Take for example statistical downscaling of precipitation. Machine learning algorithms are trained on rainfall data from reanalyses and in-situ observations, and thus learn how to connect large-scale fields and local precipitation. This “knowledge” can then be applied to low-resolution climate simulations, allowing to get an estimate of the local precipitation values that was not available in the original data. A similar engineering approach is “short-cutting” expensive computations in climate models, for example in the radiation schemes. If trained on a set of calculations performed with a complex radiation scheme, a machine learning algorithm can then provide approximate solutions for new climatic conditions and thus prevent the need to re-run the scheme at every time-step in the real model simulation, making it computationally very effective.
However, next to this engineering approach, there are also ways to use machine learning methods in order to actually gain new understanding. For example, in systematically changing the extent of input data, one can try to find out which part of the data is relevant for a specific task. For example “which parts of the atmosphere provide the information necessary to predict precipitation/windspeeds above a specific city and at a specific height?
As final point, artificial intelligence and machine learning techniques are widely used in research and industry, and will evolve in the future independent of their use in climate research. Therefore, they provide an opportunity of getting new techniques “for free”: an opportunity which can and should be used.
[1] scikit-learn.org
This article has been edited by Gabriele Messori and Célia Sapart.