Berlin just went through a brutal heatwave, and then out of nowhere, the temperature crashed between June 28 and 29. The daily mean temperature dropped from nearly 33°C to 25°C—a dramatic drop of about 8°C in just 24 hours (based on ERA5 reanalysis data structure accessed via Open-Meteo). Scientists call these abrupt shifts temperature volatility: rapid transitions from unusually cold to warm cond ...[Read More]
Sudden Temperature Change in a Warming World: Why Future Temperature Swings Are a Global Tug-of-War?
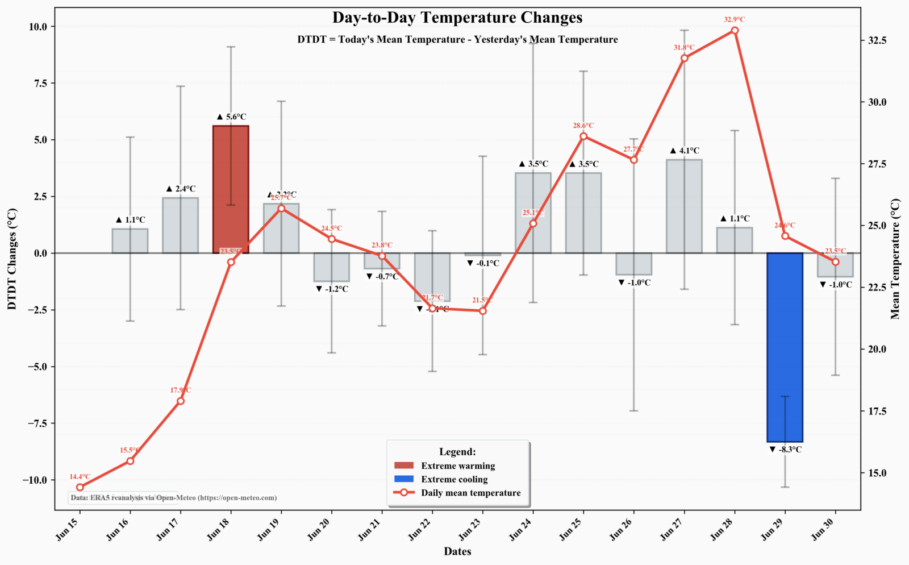
Day-to-day temperature changes in Berlin, June 15–30, 2026. Red bars = Extreme warming, and blue bars = Extreme cooling. The red line shows the daily mean temperature. Data: ERA5 via Open-Meteo.


