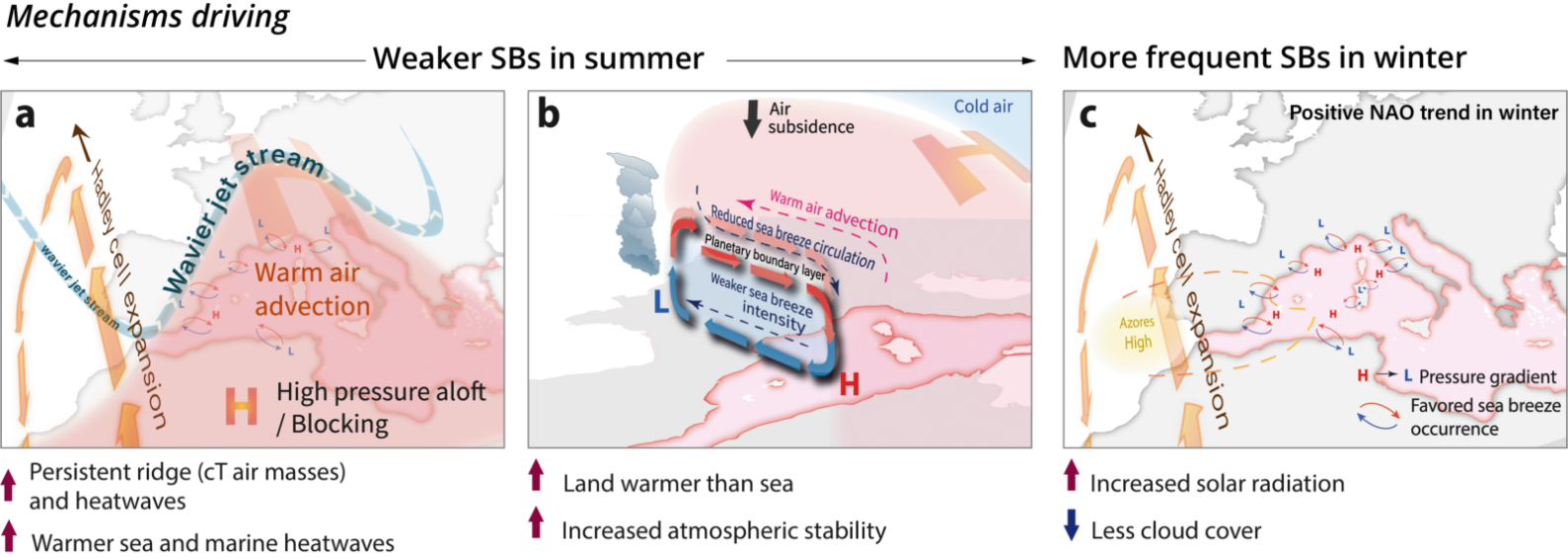
Every time something burns incompletely —whether in a car engine, a factory furnace, a cooking fire, an agricultural field set alight after harvest, or a vast wildfire sweeping through savanna grasslands— tiny particles of black carbon are released into the atmosphere. You might know these more simply as soot. These particles are so small that thousands of them laid side by side would barely stret ...[Read More]
Why the Same Soot Can Warm One City and Cool Another
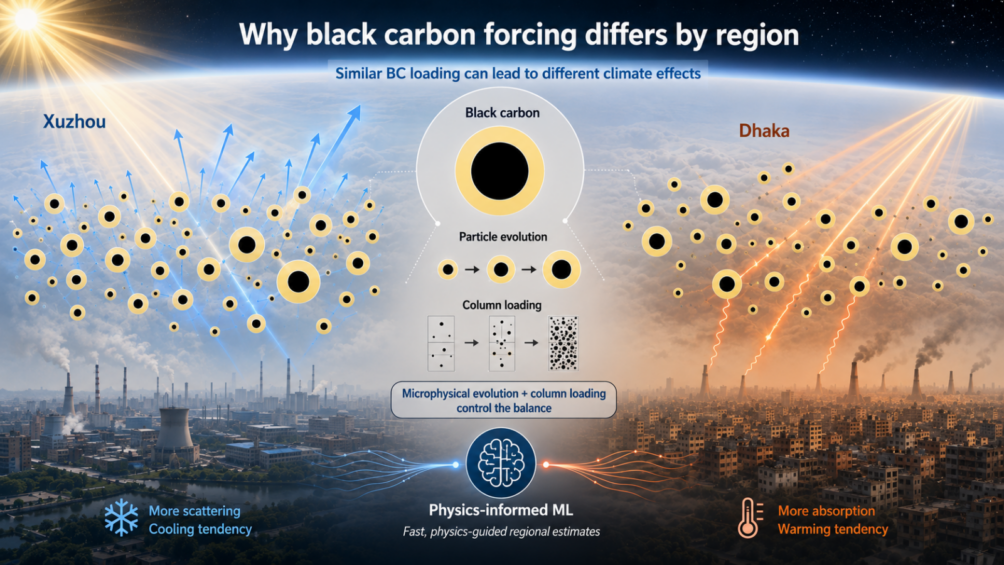
Graphical abstract of the study. Authors' courtesy