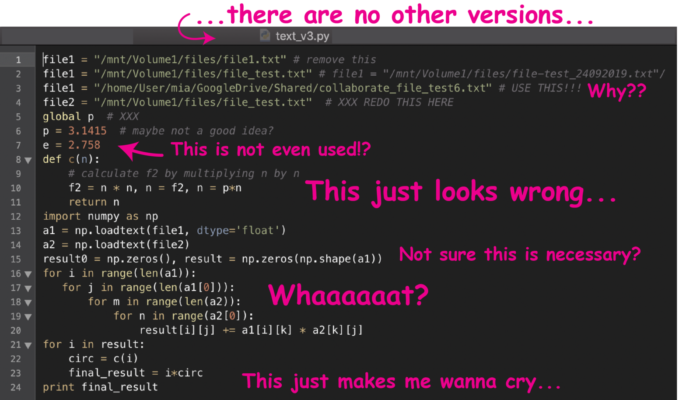
Tell me if this sounds familiar to you:
Act I
After a fruitful discussion with a colleague, you exchange codes and algorithms. You are happy because you are convinced you will save some time through this collaboration and you don’t need to develop the same codes yourself.
Act II
The drama unfolds slowly. Firstly, you search without success for a README file or instructions on how to execute the code. Secondly, the codes simply don’t work because parts of it have been hardcoded. Also, the more you dig into the codes, the more you realize some libraries cannot be compiled on your machine, for example, the legacy codes that we are all familiar with in geosciences. You leave the stage in tears.
Act III
You accuse your colleague of foul play and sabotaging your work. Why did he/she have to use Fortran 77, Ratfor, GMT3, or python2.7 for a simple job such as cross-correlating two waveforms? In the last scene, you rewrite the whole workflow yourself, maybe in Python 3 or in Julia, spend time on rewriting those algorithms, and at the same time, make them faster, more efficient, and neater. You type “git push”.
The curtain falls. Standing ovation.
A lot of codes written by earth scientists look like somebody used a hammer and an ice pick, and in the end, everything is “fixed” with duct tape.
Why am I talking about this?
Parts of act I, II, and III happened to me in real life and on several occasions. I am still waiting for the “standing ovation”, though. I’m sure most of you had a similar experience, being on the receiving side of unusable and unreadable codes. Nothing can be reproduced! If, dear reader, you are on the giving side, shame on you and noisy seismograms for the end of your research career. (Just kidding!)
Most seismologists I know have a background in earth sciences, physics, engineering, or maths. Thinking back to my programming classes in undergrad, I can say with certainty that I did not learn anything useful about “best practices” in developing usable and shareable codes. Once I started my DPhil project, I learned and understood some important programming lessons … the hard way.
Most of us learned programming by looking at other people’s codes, StackOverflow, and GeekforGeeks without proper training in software development. Most of us are not even aware of the shortcomings in our codes; we never learned them.
As an analogy, it’s similar to the problem of which tool to use for a specific job. A lot of codes written by earth scientists look like somebody used a hammer and an ice pick (e.g. mixing various coding languages to do one simple job), and in the end, everything is “fixed” with duct tape (aka, hard coding).
Why should YOU care?
“But we are not software engineers!” some of you may think, “Why should we care if a code is well-written as long as it does what it is supposed to do?”. Some claim “we are not rewarded by writing good software libraries. We should publish the results [once and only once]”.
Reproducibility is the short answer!
How many times has it happened to you that you wanted to reuse your code after a year, a couple of months, or even a few weeks and discovered that you cannot even run it anymore? No README is in place, no comments in the code, you are sure you made some changes before you moved to another project, but for the love of git, you don’t remember what you changed, and unfortunately, there is no way to check.

The demand for reproducibility is growing every day. Nowadays, some journals ask the authors to share their data and codes on open-access repositories. Unfortunately, in many papers, the authors decide to add a line “the codes are available upon request”. Although this is good enough for some journals, the community never gets access to those codes.
We need to take actions ourselves, as researchers! In seismology, in contrast to many other fields, the majority of our datasets are publicly available. This is amazing, but we need to take this one step further. We need to provide the community with well-tested and reproducible software libraries. Reproducible codes can be double- and triple-checked by others. They can build upon our years of work on developing codes and ideas, and in return, we can save a tremendous amount of time by using community codes. Various people will check these codes, and the result is a set of well-tested robust codes and software libraries. This demand for reproducible research will grow even more in the future, and it is better to be prepared for this rather sooner than later.
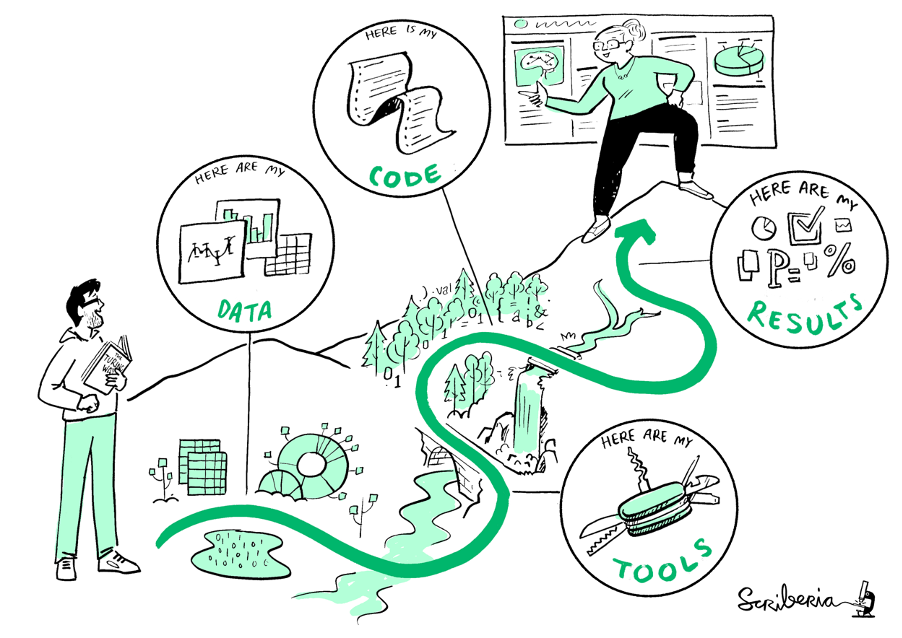
Reproducible Research. Illustration from The Turing Way website: https://the-turing-way.netlify.app/reproducible-research/reproducible-research.html (Zenodo. http://doi.org/10.5281/zenodo.3332807)
The point of sharing codes is to find mistakes, fix them, and make a software library better. Together.
How did we get here?
Well, most of us never even learned (or heard of) “best practices in programming”, so how do we expect to implement them? These are topics usually taught in software engineering degrees. In our earth science undergrads, if we have any programming courses at all, we normally learn some basics in programming (e.g., for-loop, if-condition, and function), work on some simple projects, and we are left in the wild! We never learn about reproducibility, ways to contribute to projects with large codebases, version controlling, unit testing, and many more.
The situation gets even worse when your supervisor is only interested in the results. This mentality encourages “disposable” codes which result in reinventing the wheel over and over again by all of us, even in one research group.
A lot of scientists don’t even want to share their codes because they are afraid that others would find a mistake in them or that they are being ridiculed for bad codes. The point of sharing codes is to find mistakes, fix them, and make a software library better. Together.
What shall we do?
Let’s start now! Write your suggestions on software design and code development in the comments below or just share your experience (maybe there is somebody who can learn from your experience or even help you). Here are my suggestions:
- Don’t be shy! Publish your codes (e.g., on GitHub).
- Version control (e.g., by using git and GitHub, also programs like PyCharm keep locally track of your changes!).
- Open source your codes whenever possible.
- Write README. At least explain how the codes can be run on simple/example datasets.
- In README (or in an external file), list the required packages/libraries to run your codes.
- License your codes (https://choosealicense.com/), so others can use them.
- Comment your code, particularly when you have made a decision that needs clarification, or when you have defined a variable that its name is not self-explanatory.
- If you want to read mode about reproducibility, project design, and collaboration (including version controlling, testing, and many more), I would suggest The Turing Way (https://the-turing-way.netlify.app/welcome.html). Again, feel free to add any other resources in the comments below that you think could help others.
This is the start of a short series of interviews with software engineers explaining the importance of good practices in software development, so please add your comments/questions/experience below. We will make sure to answer most of those questions in our upcoming interviews.
… and for the love of version control, git your codes.

Robert Delhaye
First lessons we learnt in undergraduate Computer Science:
1) Computers only do what we tell them to do (we’re just not always clear about what we’re asking).
2) Comment your code. We did get bonus marks for simply having comments, no matter if useful or not.
3) No “magic numbers” in your code – pi might be the only allowable exception…
4) Get a soft toy or rubber duck, put it on your desk, explain your (programming) problems to it. Often, the process of formulating the problem into words gives insight into what you need to fix.
I can’t say I always remember these, but I’ve found they often help, especially 2 & 3 when revisiting code.